
현재 상황
@Entity
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PUBLIC)
@Table(indexes = @Index(name = "oauth_id", columnList = "oauthId", unique = true))
public class Member extends BaseTimeEntity implements UserDetails {
@Id
private String id;
@Column(nullable = false)
private String oauthId;
@Enumerated(EnumType.STRING)
private OAuthProvider oauthPlatform;
@Column(nullable = false)
private String name;
private String profileImg;
@Column(nullable = false)
private String nickname;
private Integer birth;
private String gender;
private String profession;
@Column(nullable = false)
private String signatureColor;
@Column(nullable = false)
private String email;
...
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
return AuthorityUtils.commaSeparatedStringToAuthorityList(role);
}
public void createMemberId() {
this.id = System.currentTimeMillis() + RandomValueUtil.createRandomString(7);
}
}
코드를 보면 @Id 즉 기본키를 지정하는 어노테이션이 붙어있는 필드 값이 String 인 것을 볼 수 있습니다.
그리고 흔하게 보이는 생성 전략을 설정하지 않았음을 볼 수 있습니다.
@Transactional
public void registMember(MemberRegistRequest memberRegistRequest) {
Optional<Member> memberOptional = findMemberByOAuthProviderAndEmailAndName(
translateStringToOAuthProvider(memberRegistRequest.oauthPlatform()),
memberRegistRequest.email(), memberRegistRequest.name()
);
if (memberOptional.isPresent()) {
throw new MemberSignupException();
}
String encodedOauthId = passwordEncoder.encode(memberRegistRequest.oauthId());
Member member = memberRegistRequest.of(encodedOauthId);
member.createMemberId();
memberRepository.save(member);
}Member를 저장할 때 member의 createMemberId를 통해 id를 설정함을 볼 수 있습니다.
public void createMemberId() {
this.id = System.currentTimeMillis() + RandomValueUtil.createRandomString(7);
}CreateMemberId에서는 현재 시각 + 랜덤 문자열 7자리를 통해 id를 값을 생성하고 있습니다.
일반적인 방법은 아니네요?
일반적인 경우 밑의 코드와 같이 생성 전략을 (IDENTITY) -> AUTO_INCREMENT로 해서 자동으로 1씩 증가하도록 구현을 합니다.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
GenerationType.IDENTITY의 사실과 오해
그러면 왜 많은 사람들이 AUTO_INCREMENT를 사용해 id를 생성할까요?
클러스터링
Mysql 버전 : 8.0.31
스토리지 엔진 : INNODB

MySQL 5.5 이후 버전부터 기본적인 스토리지 엔진으로 선택된 INNO DB에서는 기본키를 기준으로 클러스터링 되어 저장됩니다. 즉 쉽게 설명하면 기본키 값의 순서대로 디스크에 저장된다는 뜻입니다.
당연히 순서대로 저장되기 때문에 탐색 또한 빠르다.
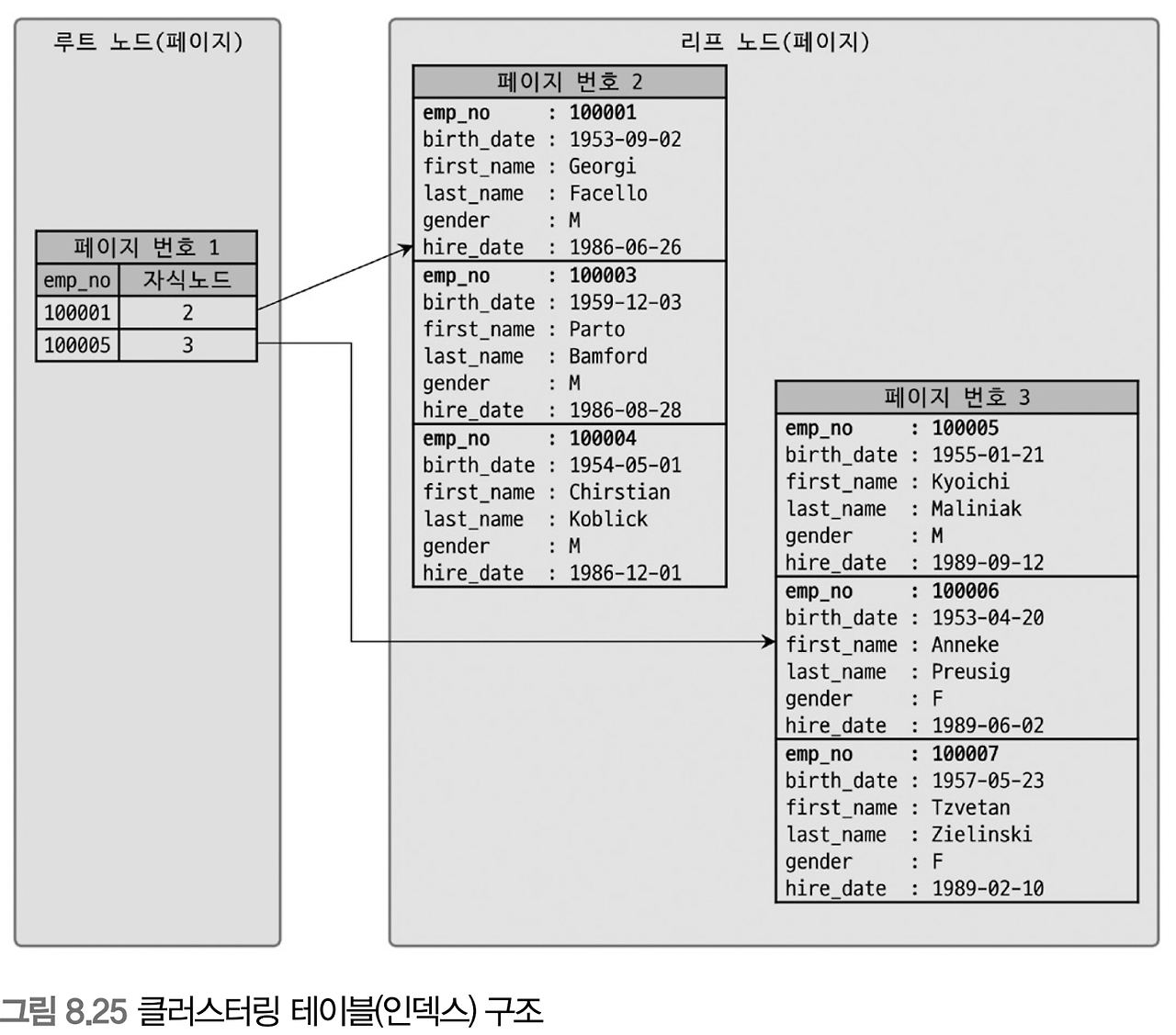
클러스터링 테이블을 살펴보면 기본키를 기준으로 비슷한 레코드끼리 묶어서 저장하는 것임을 알 수 있습니다.
SELECT * FROM tb_user WHERE emp_no=10001;위의 SQL문과 같이 emp_no가 10001인 user를 찾으려고 하면 루트 노드에서 2번 페이지를 탐색해 반환합니다.
이렇게 장점이 있으면 항상 단점도 있습니다..
만약 기본키를 변경하게 된다면 어떻게 될까요?
그냥 단순하게 하나의 필드 값만 바뀐다고 생각할 수 있지만 클러스터링 테이블의 관점에서 살펴보면 기본키가 변경된 값의 위치로 물리적인 저장 위치가 바뀌어야 합니다. 그래서 기본키의 변경은 최대한 지양을 해야 하는 것입니다.
AUTO_INCREMENT로 생성하는 PK는 효율적일까?
그러면 AUTO_INCREMENT보다 의미 있는 값으로 하는 게 좋지 않을까요?
AUTO_INCREMENT로 기본키를 설정하게 되면 물론 변경되지 않아서 물리적인 데이터 공간이 변하지 않는 장점이 있습니다. 하지만 클러스터링 인덱스의 장점이 탐색(특히 범위 탐색)임을 고려했을 때 AUTO_INCREMENT는 적절하지 않은 것 같습니다.
간단히 두 개의 이유로 설명해보겠습니다.
AUTO_INCREMENT는 특별한 값이 아니다.
AUTO_INCREMENT는 DB에서 열이 증가할 때마다 설정해 주는 값입니다.
그러므로 사용자에 따라서 특별히 정해지는 값도 아니고 개발자가 특별한 목적을 가지고 생성하는 값도 아닙니다.
자연스럽게 클러스터링 인덱스의 장점을 활용하지 못하므로 사용자에게 의미 있는 값으로 하는 것이 나을 것 같습니다.
학생은 학번, 대한민국 국민은 주민등록번호와 같이 AUTO_INCREMENT 된 값보다는 크기가 크지만 의미 있는 값으로 하는 것이 좋습니다.
AUTO_INCREMENT 된 기본키를 사용해 조회하면 보안에 문제가 생길 수 있습니다.
클러스터링 인덱스와 전혀 상관없지만, 1씩 증가하는 형식이므로 특정 테이블의 PK를 유추하기 쉽습니다.
그러므로 악의적인 공격에 취약할 수밖에 없습니다.
https://solution-is-here.tistory.com/213티스토리의 글과 같이 모두에게 공개되어 있는 문서는 큰 상관이 없습니다.
하지만 만약!
https://www.google.com/1
AUTO_INCREMENT 된 기본 키로 사용자의 정보를 조회할 수 있다고 하면 큰 문제가 될 수 있습니다.
사람들은 자연스럽게 쿼리의 맨 마지막 숫자만 바꾸면 다른 사람들의 정보를 조회할 수 있게 됩니다.
UUID에 대한 사실

이와 같이 UUID는 매우 복잡하며 PK의 무결성 규칙을 지킬 수 있습니다.
UUID에 대해 자세히 알고 싶으면 밑의 링크를 방문하시는 것을 추천합니다.
https://docs.tosspayments.com/resources/glossary/uuid
UUID(Universally Unique Identifier) | 토스페이먼츠 개발자센터
UUID는 128-bit의 고유 식별자에요. UUID는 중앙 시스템에 등록하고 발급하는 과정이 없어서 상대적으로 빠르고 간단하게 만들 수 있어요.
docs.tosspayments.com
UUID는 밑의 코드와 같이 생성할 수 있습니다.
@Id
@GeneratedValue(strategy = GenerationType.UUID)
private UUID id;
하지만 성능상의 문제가 생길 수 있습니다.
1. 크기
UUID는 기존 정수의 byte(4) 값 보다 4배 더 큰 값을 가지고 있습니다.
자연스럽게 저장을 할 때 더 많은 저장공간을 필요로 하며 이는 생성이 자주 일어나는 테이블에서는 치명적인 단점이 될 수 있습니다.
2. 재정렬
초 / 중 / 고에서 운동회를 할 때 보통 여러분의 기본키는 키(height)였습니다.
키가 작은 학생은 앞으로 가고 키가 큰 학생은 뒤로 가면서 키를 기준으로 오름차순 정렬을 하였습니다.
이때 전학생이 왔는데 만약 전학생이 나보다 키가 크면 어떻게 될까요?
나보다 뒤에 저장되기 때문에 전혀 문제가 없습니다.
하지만 문제는 전학생이 나보다 키가 작을 때 발생합니다.
전학생이 나보다 앞에 저장되면서 자연스럽게 전학생 뒤에 있는 학생들은 모두 한 칸씩 뒤로 물리적인 위치가 옮겨집니다.
UUID의 문제가 이와 같습니다.
UUID는 랜덤으로 생성되는 값이기 때문에 값이 작을 수도 있고 클 수도 있습니다.
그러므로 매번 생성될 때마다 일부 행을 재정렬 해야 합니다.
테이블에 많은 수의 레코드가 있지 않다면 큰 문제가 되지 않을 수도 있는데 많은 수의 레코드가 있는 DB에서는 큰 문제가 될 수 있습니다.
이미 저장된 수많은 레코드들의 기본키를 UUID에서 다른 값으로 바꾸는 작업은 매우 힘드므로 초반에 잘 설계를 하는 것이 중요합니다.
현재 시간 + 랜덤 문자열 (현재 상황)
그러면 다시 현재 상황으로 돌아오겠습니다.
현재 상황을 간단히 복기하면 생성된 시간에 7자리의 문자열을 추가해 PK를 생성하는 방식이었습니다.
이 방법에 AUTO_INCREMENT, UUID의 단점들을 대입해 보겠습니다.
1. 특별한 값인가요?
아쉽게도 특별한 값이라고 자신 있게 말할 수는 없을 것 같습니다. AUTO_INCREMENT와 같이 사용자를 생성한 순서대로 정렬시키므로 사용자를 생성한 순서대로 분류시키는 경우가 아니라면 크게 성능상 이점이 없을 것 같습니다.
2. 보안성에 문제가 없나요?
AUTO_INCREMENT와 달리 현재 시간 + 랜덤 문자열을 통해 생성하는 방식은 보안성에 문제가 없을 것 같습니다.
AUTO_INCREMENT의 문제점은 다른 사용자가 PK를 통해 다른 레이블의 PK를 유추할 수 있다는 단점이 있었는데 현재 시간 + 랜덤 문자열을 통한 방법에서는 현재 시간에 7자리의 랜덤 문자열을 추가하므로 쉽게 다른 테이블의 PK를 유추할 수 없습니다.
3. 크기는 작나요?
| 특징 | 현재 시간 + 랜덤 문자열 7자리 | UUID |
| 크기 | 최대 20자리(현재 시간 13자리 + 랜덤 문자열 7자리) | 36자리 |
| 데이터베이스 공간 | 작음 | 큼 |
UUID와 비교를 했을 때 16자리(16Byte) 작은 모습을 볼 수 있습니다.
4. 재정렬 될 가능성은 없나요?
동일한 밀리초에 생성이 되면 재정렬 될 가능성이 있습니다.
하지만 1밀리초는 1/1000초이므로 고려하지 않았습니다. 만약 문제가 생긴다면 마이크로 초를 통해 생성하는 방식으로 수정해 보겠습니다.
동일한 밀리초를 고려하지 않는다면 생성된 시점이 문자열 보다 앞에 있으므로 생성된 시점을 기준으로 정렬이 됩니다.
이 경우 시간을 거슬러 생성하는 것은 불가능하기 때문에 재 정렬 될 가능성은 매우 매우 드물다고 할 수 있습니다.
결론
현재 시간 + 랜덤 문자열도 완벽한 방법은 아니라고 생각합니다.
하지만 장시간 연구를 해본 결과 완벽에 가까운 방법이라고 생각합니다.
긴 글 읽어주셔서 감사합니다. 글에 오탈자나 잘못된 내용이 있으면 댓글로 알려주시면 감사하겠습니다.