
이번 글에서는 자바를 사용하며 주로 다루게 되는 예외와 자바의 핵심 기능인 리플렉션, 그리고 그 외 기능에 대해 다뤄보겠습니다.
1. 예외
1. 예외 vs 에러
"예외 발생했어요", "에러 발생했어요"
위의 두 문구는 제가 스프링을 개발하며 들었던 말입니다.
보통 예외 == 에러라고 생각할 수 있으나, 둘은 천지차이입니다.
예외는 주로 프로그램 실행 중 발생할 수 있는 예상 가능한 문제상황을 말합니다.
프로그램의 코드나 문제, 사용자 입력으로 인해 발생하는 오류가 예외죠.
Null 객체를 호출하거나 Null 객체의 메서드, 필드에 접근할 때 발생하는 NullPointerException 등이 있습니다.
그에 비해 에러는 시스템 레벨의 심각한 문제를 나타내며 예외에 비해 복구하기 어렵습니다.
시스템 자원 부족, 하드웨어 오류 등 프로그램 외부의 요인으로 발생합니다.
무한 재귀, 순환 참조로 인해 JVM에 할당된 스택 메모리보다 프로그램의 실행에 필요한 스택 메모리가 많은 경우 발생하는 StackOverFlowError 등이 있습니다.
1 - 1 Throwable vs Exception
Error와 Exception에 대해 조금 더 자세히 알아보려면 Throwable에 대해 알아야 합니다.
하기의 사진은 Throwable에 정의되어 있는 메서드들입니다.
백엔드 개발을 하며 예외, 오류가 어디에서 일어났는지 찾아보려고 하신 분들이라면 적어도 한 번쯤은 보셨을 메서드들입니다.

Error와 Exception은 둘 다 Throwable을 상속해서 공통으로 위의 메서드들을 가지고 있던 것입니다.
Throwable -> Exception과 Error가 모두 상속을 하고 있는 상위 클래스
Exception -> Throwable을 상속하고 있는 하위 클래스
이러한 구조를 내부 코드와 함께 더 자세히 살펴보자면:
위 코드를 실행시키면 다음과 같은 메시지가 출력됩니다.
Exception in thread "main" java.lang.NullPointerException: Cannot read field "name" because "apple" is null at Main.main(Main.java:11)
이 코드가 출력되는 것을 간단히 살펴보면 NullPointerException이 발생하고, RuntimeException, Exception, Throwable의 순서로 호출이 돼 해당 메시지가 출력이 되는 것입니다.
NullPointerException의 생성자에서 부모 클래스의 생성자를 호출합니다. (RuntimeException의 생성자 호출)
RuntimeException의 생성자에서 부모 클래스의 생성자를 호출합니다. (Exception의 생성자 호출)
Exception의 생성자에서 부모 클래스의 생성자를 호출합니다. (Throwable의 생성자 호출)
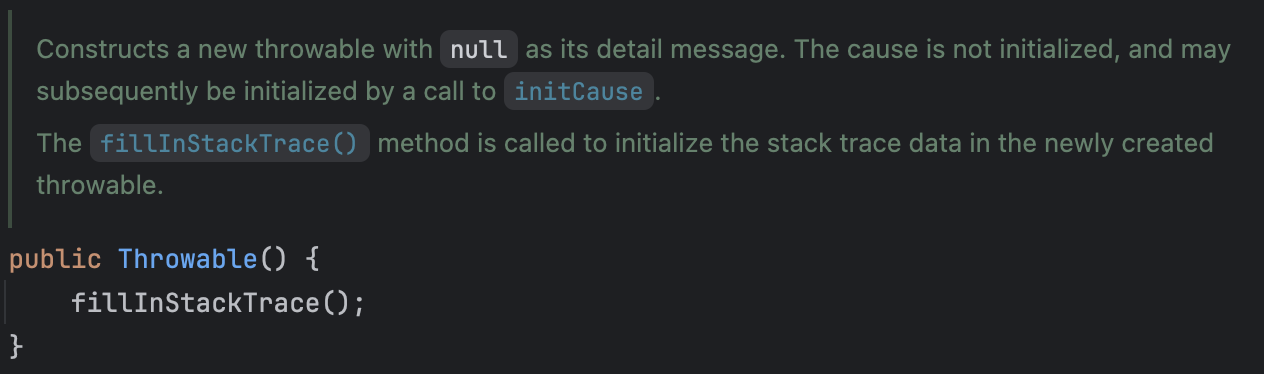
Throwable의 생성자에서 fillInStackTrace를 호출합니다.
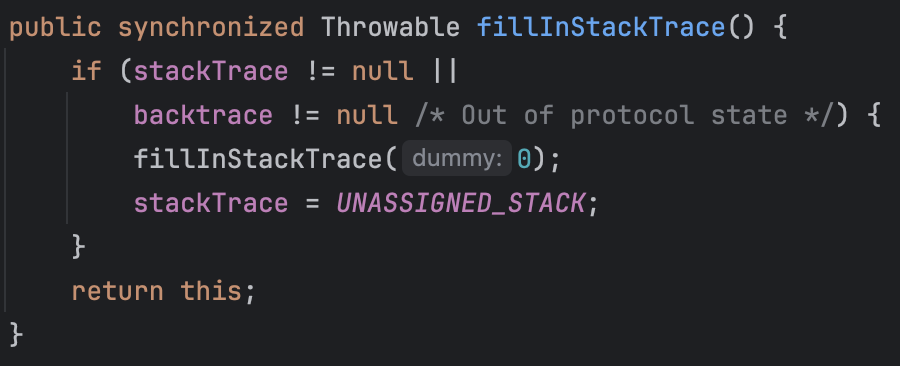
해당 메서드에서 현재 스택 트레이스의 정보를 캡쳐합니다.
그로 인해 예외 메시지가 출력이 됩니다.
2. 예외 클래스
https://docs.oracle.com/javase/8/docs/api/index.html?java/lang/Exception.html
Java Platform SE 8
docs.oracle.com
위 링크를 보면 어떤 클래스들이 Exception 클래스를 상속했는지 알 수 있습니다.
주요한 예외 몇 개를 설명하자면:
- NullPointerException : Null 객체의 속성이나 메서드에 접근하려 할 때 발생합니다.
- IllegarArgumentException : 메서드에 부적절한 인자를 전달했을 때 발생합니다.
- IOException : 입출력 작업 중 오류가 발생했을 때 발생하는 예외입니다.
그리고 이러한 예외는 CheckedException과 UnCheckedException으로 나뉩니다.
코드 단계에서 반드시 처리를 해야 하는 예외 vs 반드시 처리할 필요가 없는 예외로 쉽게 생각할 수 있습니다.
이미 아실 분도 있겠지만 RuntimeException을 상속하지 않은 예외 vs 상속하는 예외로도 나눌 수 있습니다.
하기의 링크를 보시고 해당 클래스를 상속하지 않은 예외는 CheckedException으로 생각하시면 됩니다.
https://docs.oracle.com/javase/8/docs/api/index.html?java/lang/RuntimeException.html
Java Platform SE 8
docs.oracle.com
FileNotFoundException은 IOException을 상속했고 IOException은 Exception을 상속했습니다.
즉, RuntimeException을 상속하지 않았으므로 CheckedException이고 반드시 예외 처리를 해야 합니다.

그에 비해 해당 코드에서 발생하는 NullPointerException은 RuntimeException을 상속했습니다.
즉, UnCheckedException이고 예외처리를 강제되지 않습니다.
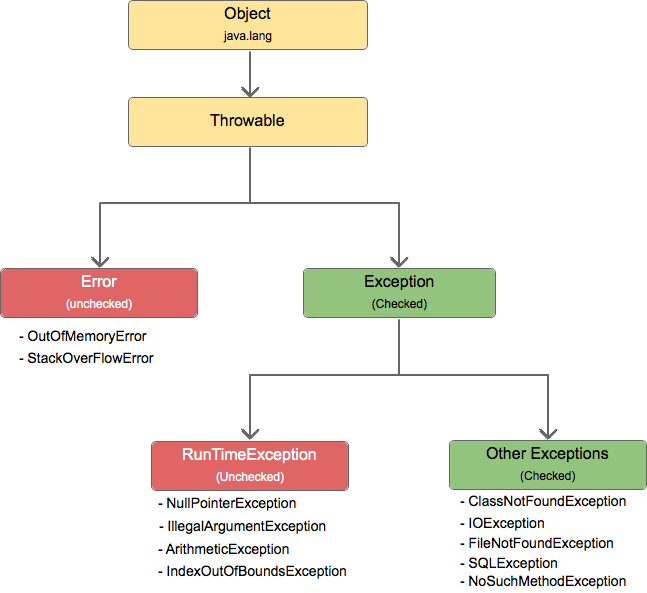
Throwable을 포함한 전체적인 클래스 구조도입니다.
3. throw vs throws
CheckedException은 반드시 예외 처리를 해야 하는데 그중 throws를 통해 예외 처리가 가능합니다.

위와 같이 throws를 통해 해당 CheckedException을 정의하면 더 이상 컴파일 에러가 일어나지 않습니다.
throws에 대해 조금 더 자세히 설명을 하자면 즉 예외를 선언하는 것입니다.
예외 처리를 해당 메서드에서 하지 않고 호출한 메서드에 위임할 때 사용합니다.
해당 메서드를 호출한 메서드에서는 똑같이 throws를 통해 예외 처리를 하거나 try-catch와 같이 다른 방법으로 예외 처리를 반드시 해야 합니다.
그에 비해 throw는 개발자가 예외를 발생시킵니다.
객체를 속성을 통해 조회했는데 DB에 해당 정보를 가지고 있는 데이터가 없다면 null이 반환되고 해당 객체의 속성이나 메서드에 접근하려고 하면 NullPointerException이 발생합니다.

그러므로 보통의 경우 개발자가 예외를 생성한 뒤 해당 예외를 발생시킵니다.
이와 같이 개발자가 직접 예외를 발생시키고 싶을 때 사용하는 것이 throw입니다.
4. try-catch-finally
예외를 강제로 발생시킬 때는 throw를 할 수도 있지만 발생할 수 있는 예외 (checked Exception, unCheckedException)을 관리하고자 할 때는 try-catch-finally를 사용할 수 있습니다.
우선 try 내에 있는 코드가 실행이 되고, 해당 코드에서 예외가 일어나면 코드를 더 이상 진행하지 않고 catch로 넘어가 예외 처리를 합니다. (catch에서 해당 예외를 처리하고 있을 때)
그리고 catch에서 예외 처리를 마친 후 finally에서 마무리 작업을 합니다.
이때 try와 catch의 역할은 분명한 것에 비해 finally의 역할은 불분명할 수 있습니다.
우선 try-catch-finally에서 finally의 역할은 예외 여부와 상관없이 실행되기 때문에 try에서 사용한 리소스를 해제하거나 정리 작업 역할을 합니다.
하지만 java 7부터 try-with-resources라는 구문이 나왔습니다.
해당 구문에서는 try가 끝나면 try 안에서 선언한 리소스들이 자동으로 해제가 됩니다.
이때 finally의 역할은 정리 작업 역할이라고 합니다.
개인적으로 동시성 관련 작업을 할 때 finally에서 unLock을 해준 경험이 있습니다.
이와 같이 예외가 발생하더라도 꼭 실행돼야 하는 코드를 finally에 정의해주는 것이 좋습니다.
2. 리플렉션
리플렉션이란 실행 중인 Java 프로그램이 스스로를 검사하고 내부 속성을 변경할 수 있게 해주는 속성입니다.
쉽게 스프링으로 설명해 보겠습니다.
스프링에는 DI(의존성 주입)이라는 개념이 있습니다.
객체 간의 의존성을 외부에서 주입을 해주는 것으로 생각하시면 됩니다.
Spring 컨테이너는 애플리케이션이 시작될 때 설정 파일이나 어노테이션을 통해 빈을 생성합니다.
이 과정에서 리플렉션을 통해 클래스 정보를 가져오고 인스턴스를 동적으로 생성합니다.
그리고 @Autowired와 같은 어노테이션을 통해 명시된 의존성을 리플렉션을 통해 주입합니다.
이때 어노테이션을 찾고, 클래스 정보를 가져오고 의존성을 주입하는 것에서 리플렉션이 사용됩니다.
1. 어노테이션
@Autowired을 통해 명시된 의존성을 주입하고, 어노테이션을 통해 빈을 생성하고...
이때 어노테이션이 뭔지 자세히 설명하겠습니다.
어노테이션은 코드에 메타데이터를 추가하는 방법입니다.
클래스, 메서드, 필드, 매개변수 등 다양한 프로그램 요소에 적용할 수 있고, 컴파일러에게 정보를 제공하거나 런타임시 특정 동작을 수행하도록 지시할 수 있습니다.
Java가 지원하는 어노테이션인 @Override를 통해 설명하겠습니다.
우선, @Override는 오버라이드를 하는 메서드에 정의를 합니다.
이때 @Override 어노테이션은 해당 메서드가 슈퍼 클래스의 메서드를 오버라이드 하고 있음을 컴파일 단계에서 컴파일러에게 정보를 전달하는 것입니다.
@Deprecated, @SuppressWarnings도 똑같이 컴파일러에게 정보를 제공하는 것입니다.
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyAnnotation {
String value();
}
public class MyClass {
@MyAnnotation(value = "Hello")
public void myMethod() {
System.out.println("My Method");
}
}코드 출처 : f-lab 자바 어노테이션과 그 활용법
위 코드를 보면 MyAnnotation이라는 커스텀 어노테이션을 볼 수 있습니다.
이때 Retention을 보면 해당 어노테이션이 런타임에도 유지가 됨을 알 수 있습니다.
런타임 어노테이션의 경우 해당 어노테이션이 붙은 클래스, 메서드, 필드가 사용될 때 처리됩니다.
myMethod가 실행되면 MyAnnotation이 처리되고 이때 리플렉션을 통해 어노테이션 정보를 읽고 Hello라는 값을 적용합니다.
실제로 제가 직접 만든 어노테이션과 함께 설명드리겠습니다.
https://github.com/IDMaker-io/MaKer
GitHub - IDMaker-io/MaKer
Contribute to IDMaker-io/MaKer development by creating an account on GitHub.
github.com
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface IDMaker {
/**
* The length of the random part of the ID.
*
* @return the length of the random part of the ID
*/
int length() default 7;
/**
* The type of characters to use for the random part of the ID.
*
* @return the type of characters to use for the random part of the ID
*/
GenerationType type() default GenerationType.EN;
}해당 어노테이션을 보면 length, type 등의 메타데이터를 가지고 있음을 볼 수 있습니다.
/**
* Checks if a field is annotated with {@link IDMaker} and if it is of type String.
*
* @param field the field to check
* @return true if the field is annotated with {@link IDMaker} and is of type String, false otherwise
* @throws IDMakerInvalidArgumentException if the field is annotated with
* {@link IDMaker} but is not of type String
*/
private boolean isIDMakerAnnotated(Field field) {
if (!field.isAnnotationPresent(IDMaker.class)) {
return false;
}
if (field.getType() != String.class) {
throw new IDMakerInvalidArgumentException(IDMAKER_ANNOTATION_ON_NON_STRING.getMessage());
}
return true;
}
/**
* Generates an ID for a field if it is null.
*
* @param entity the entity that contains the field
* @param field the field for which to generate an ID
* @throws IDMakerAccessException if there is an error accessing the field
*/
private void generateIdForField(Object entity, Field field) throws IDMakerAccessException {
field.setAccessible(true);
try {
if (field.get(entity) == null) {
IDMaker idMaker = field.getAnnotation(IDMaker.class);
String generatedId = IDMakerUtils.createTimestampedRandomID(idMaker.length(), idMaker.type());
field.set(entity, generatedId);
}
} catch (IllegalAccessException e) {
throw new IDMakerAccessException(FAILED_TO_ACCESS_FIELD.getMessage(), e);
}
}위 코드에서 field에서 어노테이션이 적용되어 있는지 확인하고, getAnnotation을 통해 어노테이션의 메타데이터를 가져옴을 볼 수 있습니다.
또한, field.set을 통해 런타임 도중 필드의 정보를 변경함을 볼 수 있습니다.
이때 field에 어노테이션이 적용되어 있는지 확인하고, 필드의 정보를 변경하는 것에 활용된 것이 리플렉션입니다.
결과적으로 어노테이션이 적용된 필드에 랜덤한 값이 생성됩니다.
jpa의 @GenerateValue와 같은 역할을 함.
3. 제네릭
List<Integer> integers = new ArrayList<>();
위 코드를 한 번이라도 보신 분이 있다면 여러분은 이미 제네릭을 사용하고 계십니다.
제네릭이란 컴파일 시점에 클래스나 메서드 내부에서 사용할 데이터 타입을 지정하는 것입니다.
이를 통해 다양한 객체의 타입을 다룰 수 있습니다.
실제로 ArrayList 클래스를 보시면 제네릭을 볼 수 있습니다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable타입 파라미터를 통해 E(Element)를 받는 것을 볼 수 있습니다.
이때 E는 여러분이 타입 파라미터 안에 작성하는 클래스입니다.
따라서 Integer.class를 넣으면 E는 Integer.class가 됩니다.
public E get(int index) {
rangeCheck(index);
return elementData(index);
}자연스레 리스트의 요소를 가져오는 get 메서드의 반환 타입도 사용자가 타입 파라미터 안에 작성하는 클래스입니다.
Integer를 넣으면 Integer를 반환하기 때문입니다.
Generic vs Object
실제로 FixtureMonkey에서 여러 객체를 받아야 할 때 제네릭을 사용한 적이 있습니다.
이때 제네릭과 Object를 고민했습니다.
Object는 모든 클래스들의 상위 클래스입니다.
즉 모든 클래스는 Object로 형 변환(업 캐스팅)을 할 수 있습니다.
하지만, 제네릭은 컴파일 시점에 데이터 타입을 결정하지만, Object는 런타임 도중 형 변환이 일어나기 때문에 ClassCastException이 발생할 수 있습니다.
이러한 점을 고려해 Generic을 선택하였습니다.
다시 프로젝트로 돌아와서 설명을 하자면, 연산을 선택하는 로직에 연산에 대한 metadata가 필요했습니다.
이때 연산의 metadata는 String이 될 수도 있고 특정 클래스가 될 수 있습니다.
그로 인해 확장성을 고려해 다양한 클래스를 사용할 수 있게 설계를 하려고 했습니다.
이때 Generic을 사용해 데이터 타입을 컴파일 시점에 결정하도록 했습니다.
fixture-monkey/fixture-monkey-api/src/main/java/com/navercorp/fixturemonkey/api/matcher/MatcherMetadata.java at c7dc4fbdbad56f47
Let Fixture Monkey generate test instances including edge cases automatically - naver/fixture-monkey
github.com
4. 람다, 스트림
1. 람다
람다란 메서드를 간단하게 식으로 표현한 것입니다.
쉽게 익명 함수를 만드는 것으로 생각하셔도 됩니다.
람다를 적용하면 메서드의 이름과 반환 값이 없어지기 때문에 익명 함수라고도 합니다.
// 기존 익명 클래스 방식
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Hello, world!");
}
};
Runnable runnable = () -> System.out.println("Hello, world!");
람다 표현식을 사용하기 위해서는 함수형 인터페이스가 필요합니다.
함수형 인터페이스는 자바에서 함수형 프로그래밍을 지원하기 위해 도입ㅈ
함수형 인터페이스는 default, static 메서드를 제외한 단 하나만의 추상 메서드만을 가집니다.
그리고 @FunctionalInterface 어노테이션을 통해 명시를 합니다.
이 규칙 덕분에 자바는 람다 표현식이 어떤 메서드를 구현하는지 명확하게 알 수 있습니다.
함수형 인터페이스는 자바에서 메서드를 1급 객체로 다룰 수 있게 해줍니다.
즉, 메서드를 인자처럼 전달하고 메서드의 반환값으로 사용 가능하게 해줍니다.
1급 객체란?
함수의 인자로도 넘겨질 수 있고 변수에 대입도 가능한 다른 요소와 차별이 없는 객체
함수형 프로그래밍은 선언적 코드 스타일을 지향하는 패러다임으로, 함수와 데이터 변환을 중심으로 구성합니다.
주로 입력을 받아 결과를 반환하는 함수들을 조합하여 프로그램을 설계합니다.
람다는 자바에서 이러한 함수형 프로그래밍이 가능하게 했습니다.
기존의 객체지향 프로그래밍은 함수형 프로그래밍과 다르게 객체와 클래스를 중심으로 프로그램을 구성합니다.
2. 스트림
자바에서 스트림은 Java 8에 도입된 강력한 데이터 처리 기능입니다.
스트림은 데이터 소스를 추상화하고 데이터를 일관된 방식으로 처리할 수 있게 해주는 객체입니다.
중간 연산, 최종 연산으로 나뉘며 코드의 가독성과 유지보수성이 향상됩니다.
public class StreamExample {
public static void main(String[] args) {
// 예제 리스트 생성
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eve");
// 중간 연산 및 최종 연산 수행
List<String> filteredNames = names.stream()
.filter(name -> name.length() > 3) // 중간 연산: 길이가 3 초과인 이름 필터링
.map(String::toUpperCase) // 중간 연산: 이름을 대문자로 변환
.sorted() // 중간 연산: 이름을 알파벳 순으로 정렬
.collect(Collectors.toList()); // 최종 연산: 리스트로 수집
// 결과 출력
System.out.println("Filtered and transformed names: " + filteredNames);
}
}
스트림은 람다와 동일하게 함수형 프로그래밍을 자바에 적용시키기 위해 도입됐습니다.
또한 대용량 데이터를 처리할 때 병렬 처리를 용이하게 하기 위해 도입 됐습니다.
5. System.out.println의 성능
현업에 계신 분께 코드리뷰를 받으면 항상 말을 하시는게 System.out.println은 사용하면 안 돼요입니다.
오늘은 그 이유를 한 번 살펴보려고 합니다.
하기의 코드는 println의 코드입니다.
synchronized 키워드가 붙은 것을 볼 수 있습니다.
이는 여러 스레드가 println 메서드에 동시에 접근했을 때 하나의 스레드만 접근할 수 있는 것을 의미합니다.
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
그로인해 A 스레드에서 println을 실행시키면 모두 사용하고 잠금을 해제한 뒤, 다른 스레드에서 println에 접근할 수 있습니다.
한 번 요청 시 5000명의 사용자를 요청하고, 처리 과정에서 응답시간이 20초 걸리는 사이트가 있는데, 원인을 알아보니 5000명의 정보를 다 System.out.println()으로 처리하고있던 것이다. 이는 System.out.println()을 줄임으로써 응답시간이 6초까지 줄었다. - 이상민, 자바 성능 튜닝이야기, 인사이트, 2013