
이 글에서는 JPA의 내부 구조에 대해 자세히 다뤄보려 합니다.
Spring Boot를 실행시키면 JpaRepository는 어떻게 생성되나요?
public interface MemberRepository extends JpaRepository<Member, Long>
아마 위 코드는 스프링으로 개발하시는 분이라면 한 번이라도 작성해봤을 코드입니다.
레포지토리 인터페이스를 정의한 뒤, 제네릭 타입으로 엔티티 클래스와 해당 엔티티의 ID 필드 타입을 지정합니다.
이렇게 하면 Spring Data JPA가 자동으로 해당 엔티티에 대한 기본적인 CRUD 작업을 수행하는 구현체를 생성합니다.
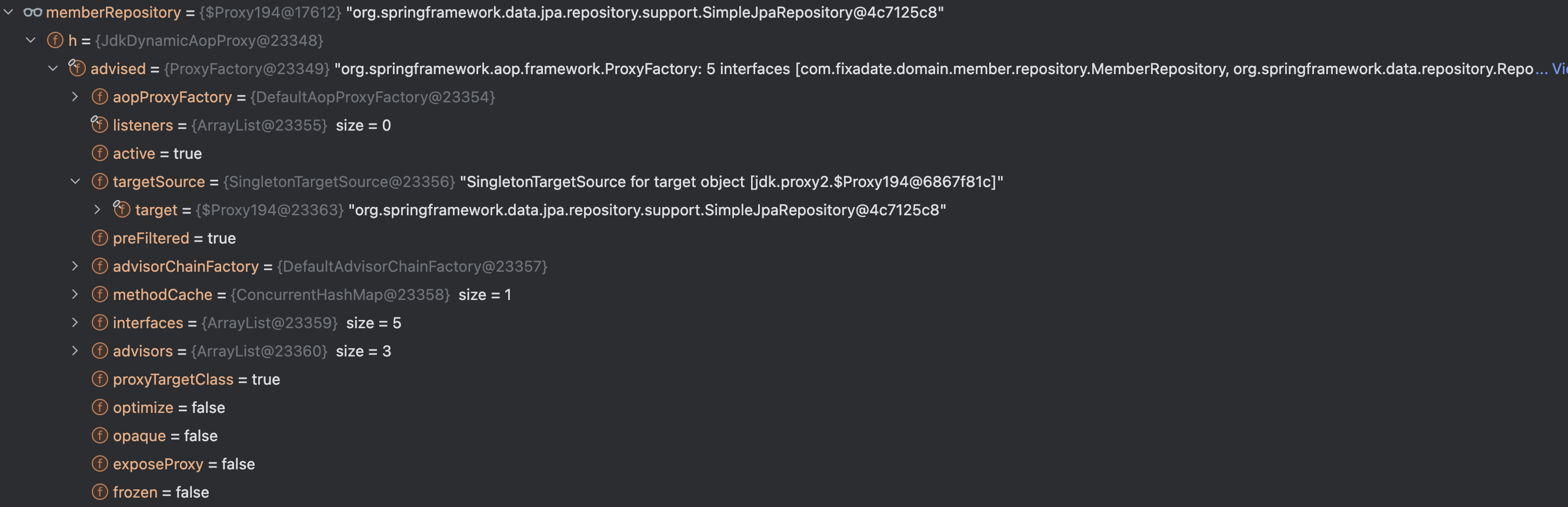
분명 MemberRepository는 interface인데 왜 Proxy가 적용됐고 Target Class가 SimpleJpaRepository야?
Spring Boot가 JpaRepository를 프록시화 시키는 주요한 이유로는
- 동적 구현 : Spring Data JPA는 인터페이스만 정의하면 실제 구현체를 동적으로 생성합니다.
이때 프록시를 통해 이를 구현합니다. - AOP 지원 : 프록시를 사용하면 횡단 관심사를 쉽게 적용할 수 있습니다.
- 트랜잭션 관리 : 프록시를 사용하면 트랜잭션을 시작하고 종료할 수 있습니다.
Spring Boot 프로젝트를 실행시키면 내장되어 있는 @EnableJpaRepositories를 통해 레포지토리 인터페이스를 활성화시키고 스캔합니다.
레포지토리를 식별하고, 스캔하는 코드는 스킵하겠습니다.
//getTargetRepository를 통해 TargetClass를 가져온다.
Object target = getTargetRepository(information);
repositoryTargetStep.tag("target", target.getClass().getName());
repositoryTargetStep.end();
RepositoryComposition compositionToUse = composition.append(RepositoryFragment.implemented(target));
validate(information, compositionToUse);
// Create proxy
StartupStep repositoryProxyStep = onEvent(applicationStartup, "spring.data.repository.proxy", repositoryInterface);
ProxyFactory result = new ProxyFactory();
result.setTarget(target);
result.setInterfaces(repositoryInterface, Repository.class, TransactionalProxy.class);
if (MethodInvocationValidator.supports(repositoryInterface)) {
result.addAdvice(new MethodInvocationValidator());
}
result.addAdvisor(ExposeInvocationInterceptor.ADVISOR);
if (!postProcessors.isEmpty()) {
StartupStep repositoryPostprocessorsStep = onEvent(applicationStartup, "spring.data.repository.postprocessors",
repositoryInterface);
postProcessors.forEach(processor -> {
StartupStep singlePostProcessor = onEvent(applicationStartup, "spring.data.repository.postprocessor",
repositoryInterface);
singlePostProcessor.tag("type", processor.getClass().getName());
processor.postProcess(result, information);
singlePostProcessor.end();
});
repositoryPostprocessorsStep.end();
}
if (DefaultMethodInvokingMethodInterceptor.hasDefaultMethods(repositoryInterface)) {
result.addAdvice(new DefaultMethodInvokingMethodInterceptor());
}
Optional<QueryLookupStrategy> queryLookupStrategy = getQueryLookupStrategy(queryLookupStrategyKey,
evaluationContextProvider);
result.addAdvice(new QueryExecutorMethodInterceptor(information, getProjectionFactory(), queryLookupStrategy,
namedQueries, queryPostProcessors, methodInvocationListeners));
result.addAdvice(
new ImplementationMethodExecutionInterceptor(information, compositionToUse, methodInvocationListeners));
T repository = (T) result.getProxy(classLoader);
repositoryProxyStep.end();
repositoryInit.end();
if (logger.isDebugEnabled()) {
logger
.debug(LogMessage.format("Finished creation of repository instance for %s.",
repositoryInterface.getName()));
}
return repository;RepositoryFactorySupport의 메서드입니다.
getTargetRepository를 통해 타겟 클래스를 가져온 뒤, 프록시를 적용시키고 반환합니다.
StartupStep repositoryProxyStep = onEvent(applicationStartup, "spring.data.repository.proxy", repositoryInterface);
ProxyFactory result = new ProxyFactory();
result.setTarget(target);
result.setInterfaces(repositoryInterface, Repository.class, TransactionalProxy.class);프록시를 생성할 때 사용자가 정의한 레포지토리, Repository.class, TransactionalProxy.class를 구현함으로써 Spring Data는 이 프록시를 레포지토리로 인식하고, 트랜잭션 관리 기능을 가지게 됩니다.
이로 인해 이 프록시를 통해 트랜잭션 경계를 설정하고 관리할 수 있게 됩니다.
TargetClass는 어떻게 가져와?
@Override
protected final JpaRepositoryImplementation<?, ?> getTargetRepository(RepositoryInformation information) {
JpaRepositoryImplementation<?, ?> repository = getTargetRepository(information, entityManager);
repository.setRepositoryMethodMetadata(crudMethodMetadataPostProcessor.getCrudMethodMetadata());
repository.setEscapeCharacter(escapeCharacter);
return repository;
}JpaRepositoryFactory의 메서드입니다.
자세히 보시면 파라미터로 RepositoryInformation이라는 인터페이스를 받습니다.
RepositoryInformation은 인터페이스 이름 그대로 Repository에 대한 정보를 담고 있는 인터페이스입니다.
레포지토리의 정보와 함께 불변 필드로 정의한 entityManager를 getTargetRepository 메서드에 전달 인자로 넘겨 JpaRepository 구현체를 받습니다.
/**
* Callback to create a {@link JpaRepository} instance with the given {@link EntityManager}
*
* @param information will never be {@literal null}.
* @param entityManager will never be {@literal null}.
* @return
*/
protected JpaRepositoryImplementation<?, ?> getTargetRepository(RepositoryInformation information,
EntityManager entityManager) {
JpaEntityInformation<?, Serializable> entityInformation = getEntityInformation(information.getDomainType());
Object repository = getTargetRepositoryViaReflection(information, entityInformation, entityManager);
Assert.isInstanceOf(JpaRepositoryImplementation.class, repository);
return (JpaRepositoryImplementation<?, ?>) repository;
}JpaRepositoryFactory의 메서드입니다.
주석을 보시면 주어진 entityManager과 함께 JpaRepository 인스턴스를 생성한다는 것을 알 수 있습니다.
코드를 자세히 보시면 getEntityInformation이라는 메서드를 통해 전달받은 RepositoryInformation의 도메인 타입을 가져오는 것을 알 수 있습니다.
예를 들어 JpaRepository <Member, Long> 이면 Member.class를 반환합니다.
그리고 JpaEntityInformation를 생성한 뒤, getTargetRepositoryViaReflection에 전달합니다.
/**
* Creates a repository of the repository base class defined in the given {@link RepositoryInformation} using
* reflection.
*
* @param information
* @param constructorArguments
* @return
*/
protected final <R> R getTargetRepositoryViaReflection(RepositoryInformation information,
Object... constructorArguments) {
Class<?> baseClass = information.getRepositoryBaseClass();
return instantiateClass(baseClass, constructorArguments);
}RepositoryFactorySupport의 메서드입니다.
우선 그전에 Reflection에 대해 간단히 설명하겠습니다.
Reflection이란 구체적인 클래스 타입을 알지 못하더라도 그 클래스의 메서드, 타입, 변수들에 접근할 수 있도록 해주는 자바 API를 말합니다.
이 메서드는 레포지토리 구현체를 Reflection을 통해 생성하는 메서드입니다.
RepositoryInformation의 getRepositoryBaseClass를 통해 레포지토리의 기본 클래스를 가져오며, instantiateClass 메서드를 통해 인스턴스를 동적으로 생성합니다. 이후, 생성한 인스턴스를 반환합니다.
Object repository = getTargetRepositoryViaReflection(information, entityInformation, entityManager);
Assert.isInstanceOf(JpaRepositoryImplementation.class, repository);
return (JpaRepositoryImplementation<?, ?>) repository;
}JpaRepositoryFactory의 메서드입니다.
getTargetRepositoryViaReflection을 통해 repository를 생성하면, assert를 통해 repository가 JpaRepository의 구현체인지 판단합니다.
그런 뒤, 업 캐스팅을 통해 구현체로 반환을 합니다.
@Override
protected final JpaRepositoryImplementation<?, ?> getTargetRepository(RepositoryInformation information) {
JpaRepositoryImplementation<?, ?> repository = getTargetRepository(information, entityManager);
repository.setRepositoryMethodMetadata(crudMethodMetadataPostProcessor.getCrudMethodMetadata());
repository.setEscapeCharacter(escapeCharacter);
return repository;
}JpaRepositoryFactory의 메서드입니다.
다시 처음 코드로 돌아와서 설명하자면, getTargetRepository를 통해 동적으로 레포지토리 구현체를 생성했습니다.
그런 뒤, CRUD 메서드에 대한 메타데이터를 레포지토리에 설정합니다.
마지막으로 SQL 쿼리에서 사용될 이스케이프 문자를 설정한 뒤, 반환합니다.
public interface MemberRepository extends JpaRepository<Member, Long> {
이제 여러분은 Proxy가 적용된 SimpleJpaRepository가 적용되는 로직을 이해했습니다.
findBy~~ 가 선언되면?
프록시 객체가 생성되면, QueryExecutorMethodInterceptor을 사용해 메서드 호출을 가로챕니다.
이때 QueryExecutorMethodInterceptor의 invoke 메서드가 호출이 됩니다.
@Override
@Nullable
public Object invoke(@SuppressWarnings("null") MethodInvocation invocation) throws Throwable {
Method method = invocation.getMethod();
QueryExecutionConverters.ExecutionAdapter executionAdapter = QueryExecutionConverters //
.getExecutionAdapter(method.getReturnType());
if (executionAdapter == null) {
return resultHandler.postProcessInvocationResult(doInvoke(invocation), method);
}
return executionAdapter //
.apply(() -> resultHandler.postProcessInvocationResult(doInvoke(invocation), method));
}메서드의 반환 타입에 맞는 ExecutionAdapter를 가져옵니다.
이때 executionAdapter가 null이면 doInvoke를 호출해서 실제 메서드 실행 결과를 얻습니다.
그 후, resultHandler를 통해 후처리 합니다.
만약 executionAdapter가 Null이 아니라면 apply 메서드를 이용해 doInvoke 메서드의 실행 결과를 후처리 합니다.
@Nullable
private Object doInvoke(MethodInvocation invocation) throws Throwable {
Method method = invocation.getMethod();
if (hasQueryFor(method)) {
RepositoryMethodInvoker invocationMetadata = invocationMetadataCache.get(method);
if (invocationMetadata == null) {
invocationMetadata = RepositoryMethodInvoker.forRepositoryQuery(method, queries.get(method));
invocationMetadataCache.put(method, invocationMetadata);
}
return invocationMetadata.invoke(repositoryInformation.getRepositoryInterface(), invocationMulticaster,
invocation.getArguments());
}
return invocation.proceed();
}doInvoke에서는 hasQueryFor 조건문을 통해 해당 메서드에 대한 쿼리가 존재하는지 확인합니다.
만약 존재한다면 호출 메타데이터 캐시에서 해당 메서드에 대한 정보를 가져옵니다.
정보가 없다면 새로운 메타데이터를 생성하고, 캐시에 저장합니다.
쿼리가 존재하지 않는다면 원래의 메서드를 호출하고 결과를 반환합니다.
즉, 프록시가 메서드 호출을 가로채지 않고 원래의 메서드 구현을 그대로 실행합니다.
쿼리는 어떻게 생성돼?
이때 쿼리는 QueryExecutorMethodInterceptor의 생성자에서 생성됩니다.
그리고 QueryExecutorMethodInterceptor의 생성자는 프록시 생성 과정 중에 호출됩니다.
result.addAdvice(new QueryExecutorMethodInterceptor(information, getProjectionFactory(), queryLookupStrategy,
namedQueries, queryPostProcessors, methodInvocationListeners));RepositoryFactorySupport의 getRepository 메서드
타겟 클래스를 찾은 뒤, 프록시 적용시키고 반환하는 메서드입니다.
this.queries = queryLookupStrategy //
.map(it -> mapMethodsToQuery(repositoryInformation, it, projectionFactory)) //
.orElse(Collections.emptyMap());QueryExecutorMethodInterceptor 클래스의 생성자
메서드에 대해 쿼리를 생성한 뒤, <Method, RepositoryQuery>와 같은 형태로 매핑합니다.
더 자세한 내용은 다른 글에서 설명하겠습니다!
정리
Spring Data JPA는 UserRepository와 같은 인터페이스의 구현체를 동적으로 생성합니다.
(프록시가 적용된 SimpleJpaRepository)
구현체를 동적으로 생성하면서 메서드 가로채기를 위한 인터셉터도 생성합니다.
인터셉터를 생성하는 과정에서 인터페이스에 있는 메서드들을 쿼리로 매핑합니다.
런타임 도중 UserRepository의 메서드가 호출이 되면 프록시가 적용된 SimpleJpaRepository가 생성이 되고, 쿼리가 실행됩니다.
(캐싱처리도 합니다)